1 文本表示模型
机器学习中,挖掘影响事件结果因素的过程称为特征工程,这一步的目的是依据现有数据挖掘出对结果有影响的因素(也叫特征),然后使用这些特征对结果进行建模。
好的特征对于建模的重要性。就像我们这世界有果皆有因,一件事情发生的背后,定有各种因素在背后支撑。我们希望计算机能够帮助我们建立各种因素取值和事件结果的对应关系,但在此之前,如何确定这些因素则是个让人头疼的东西。
1.1 词嵌入
NLP,就是使用计算机处理自然语言的过程。而我们都知道,计算机只能处理数值,因此自然语言需要以一定的形式转化为数值。词嵌入就是将词语(word)映射为数字的方式。一个单纯的实数包含的信息太少,一般我们映射为一个数值向量。这时我们会发现一个问题,怎么把词语转换为数值向量?自然语言本身蕴含了语义和句法等特征,如何在转换过程中保留这些抽象的特征?这点其实很重要,因为如果没有将自然语言的特征很好的保留下来,后续的所有工作就是对一些无意义的信息进行建模,自然得不到好的结果。纵观NLP的发展史,很多革命性的成果都是词嵌入的发展成果,如Word2Vec、ELMo和BERT,其实都是很好地将自然语言的特征在转换过程中进行了保留。
2 基于统计方法的词嵌入
2.1 one hot vector
One-hot表示很容易理解。在一个语料库中,给每个字/词编码一个索引,根据索引进行one-hot表示。
John likes to watch movies. Mary likes too. John also likes to watch football games.如果只需要表示出上面两句话中的单词,可以只对其中出现过的单词进行索引编码:
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also":6, "football": 7, "games": 8, "Mary": 9, "too": 10}其中的每个单词都可以用one-hot方法表示:
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] ...当语料库非常大时,需要建立一个很大的字典对所有单词进行索引编码。比如100W个单词,每个单词就需要表示成100W维的向量,而且这个向量是很稀疏的,只有一个地方为1其他全为0。还有很重要的一点,这种表示方法无法表达单词与单词之间的相似程度,如
beautiful和pretty可以表达相似的意思但是ont-hot法无法将之表示出来。
2.2 Bag of Words
词袋表示,也称为计数向量表示(Count Vectors)。文档的向量表示可以直接用单词的向量进行求和得到。
John likes to watch movies. Mary likes too. -->> [1, 2, 1, 1, 1, 0, 0, 0, 1, 1] John also likes to watch football games. -->> [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]横向来看我们把每条文本表示成了一个向量,纵向来看,不同文档中单词的个数又可以构成某个单词的词向量。如上文中的
"John"纵向表示成[1,1]。在真实世界中,我们的语料数据通常是包含数十万到上百万篇文档的,这些文档包含的非重复词会非常多。而每篇文档包含的词语数量相对于词典中的词语数量是非常小的,这会导致词频矩阵中会出现非常多的0。所以组织词典的另外一个方式是按词语出现的频率排序,选择频率最高的前1000个词语组成词典。
扩展:Bi-gram和N-gram与词袋模型原理类似,Bi-gram将相邻两个单词编上索引,N-gram将相邻N个单词编上索引。
为 Bi-gram建立索引:
{"John likes”: 1, "likes to”: 2, "to watch”: 3, "watch movies”: 4, "Mary likes”: 5, "likes too”: 6, "John also”: 7, "also likes”: 8, "watch football": 9, "football games": 10}这样,原来的两句话就可以表示为:
John likes to watch movies. Mary likes too. -->> [1, 1, 1, 1, 1, 1, 0, 0, 0, 0] John also likes to watch football games. -->> [0, 1, 1, 0, 0, 0, 1, 1, 1, 1]这种做法的优点是考虑了词的顺序,但是缺点也很明显,就是造成了词向量的急剧膨胀。
词袋模型编码特点:
- 词袋模型是对文本(而不是字或词)进行编码;
- 编码后的向量长度是词典的长度;
- 该编码忽略词出现的次序;
- 在向量中,该单词的索引位置的值为单词在文本中出现的次数;如果索引位置的单词没有在文本中出现,则该值为 0 ;
缺点
- 该编码忽略词的位置信息,位置信息在文本中是一个很重要信息,词的位置不一样语义会有很大的差别(如 “猫爱吃老鼠” 和 “老鼠爱吃猫” 的编码一样);
- 该编码方式虽然统计了词在文本中出现的次数,但仅仅通过“出现次数”这个属性无法区分常用词(如:“我”、“是”、“的”等)和关键词(如:“自然语言处理”、“NLP ”等)在文本中的重要程度;
2.3 TF-IDF向量
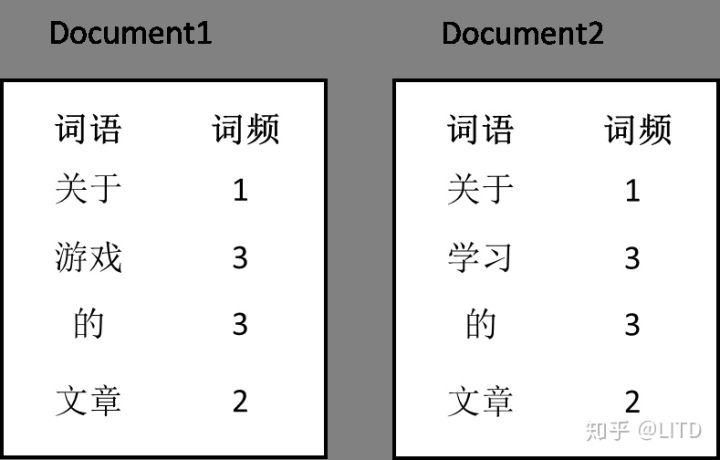
我们有两篇文档D1和D2,每篇文章中所包含的词语及其词频如下图所示:
词语频率(Term Frequency)的定义如下:
TF = (词语w在一篇文档中出现的次数)/(文档中的词语总数)
根据这个定义,可以计算TF(关于,D1) = 1/9;TF(学习,D2) = 3/9。
TF表示的是该词语对于该文档的贡献程度,我们认为与文章相关的词语出现的频率应该会比较高。
逆文档频率(Inverse Document Frequency)的定义如下:
IDF = log((文档的数量)/ (包含词语w的文档数量))
根据这个定义,得到IDF(关于) = log(2/2) = 0;IDF(游戏) = log(2/1) = 0.301。
IDF想表达的是,如果一个词语在大部分甚至所有文档中都出现(词语中的中央空调),那么这个词语对于任意一篇文档都是不重要的。
最后,TF-IDF的计算方式就是把TF和IDF相乘即可。来看一下:
TF-IDF(关于,D1) = (1/9)* 0 = 0
TF-IDF(游戏,D1) = (3/9) * 0.301 = 0.1003
TF-IDF(学习,D2) = (3/9)* 0.301 = 0.1003
这下就比较符合我们的直觉了:重要的词语(特征)应该具有更高的权重。
将词频矩阵中的词频值替换为TF-IDF值,我们就可以得到文档和词语的向量表示了。同时,由于TF-IDF的特征,TF-IDF还经常被用来提取文章中的关键词。
def def_tfidf(cls_info_lst: Dict): """ tf-idf普通实现 [06_TF-IDF算法代码示例](https://blog.csdn.net/u012990179/article/details/90338906) :param cls_info_lst: {"A":{"a":15,"b":18,...}, "B":{"c":48,...},...} :return: """ tf_dic = {} idf_res = defaultdict(int) for cls, cls_info in cls_info_lst.items(): total = sum(cls_info.values()) hy = {k: v / total for k, v in cls_info.items()} tf_dic[cls] = hy for k in set(cls_info.keys()): idf_res[k] += 1 total_doc = len(cls_info_lst) idf_res = {k: log(total_doc / (v + 1)) for k, v in idf_res.items()} cls_word_weights = [] for cls, tf_info in tf_dic.items(): t_lst = [] for k, v in tf_info.items(): t_lst.append([k, v * idf_res.get(k, 1)]) cls_word_weights.append((cls, t_lst)) return cls_word_weights优点
- 实现简单,算法容易理解且解释性较强;
- 从IDF 的计算方法可以看出常用词(如:“我”、“是”、“的”等)在语料库中的很多文章都会出现,故IDF的值会很小;而关键词(如:“自然语言处理”、“NLP ”等)只会在某领域的文章出现,IDF 的值会比较大;故:TF-IDF 在保留文章的重要词的同时可以过滤掉一些常见的、无关紧要的词;
缺点
- 不能反映词的位置信息,在对关键词进行提取时,词的位置信息(如:标题、句首、句尾的词应该赋予更高的权重);
- IDF 是一种试图抑制噪声的加权,本身倾向于文本中频率比较小的词,这使得IDF 的精度不高;
- TF-IDF 严重依赖于语料库(尤其在训练同类语料库时,往往会掩盖一些同类型的关键词;如:在进行TF-IDF 训练时,语料库中的 娱乐 新闻较多,则与 娱乐 相关的关键词的权重就会偏低 ),因此需要选取质量高的语料库进行训练;
2.4 共现矩阵 (Cocurrence matrix)
这个方法的出发点是:相似的词语会经常同时出现,并且具有相似的上下文。比如:苹果是水果。香蕉是水果。苹果和香蕉具有相似的上下文。
在深入词共现矩阵的构造和定义之前,我们先来介绍两个概念:共现和上下文窗口。
共现 — 对于给定的语料,共现指词语w1和词语w2在给定上下文窗口中共同出现的次数。
上下文窗口 — 计算共现时所指定的窗口大小,由距离和方向指定。
同样以一个例子来说明:
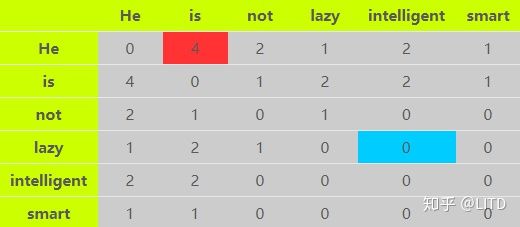
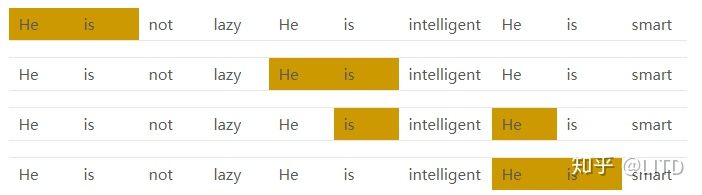
Corpus = He is not lazy. He is intelligent. He is smart.
给定距离2和双向的上下文窗口,该例的词共现矩阵如下:
以图中的红色框和蓝色框为例。红色框表示“He”和“is”的共现次数为4,如下图所示:
而蓝色框值为0,代表词“lazy”从未出现在词“intelligent”的方圆两词之内。
在词共现矩阵中,我们可以使用行向量或者列向量来表示词语(矩阵是对称的)。但存在的问题与词频矩阵相似,向量的维度等于词典的大小V,这将导致向量是稀疏且高维的,不利于计算。在实际使用中,通常是使用PCA或SVD等技术,将词共现矩阵降维为V×k(k<<V)的大小,这样,每个词语将使用一个k维大小的向量来表示。
优点
- 考虑了句子中词的顺序;
缺点
- 词表的长度很大,导致词的向量长度也很大;
- 共现矩阵也是稀疏矩阵(可以使用 SVD、PCA 等算法进行降维,但是计算量很大);
2.5 pmi计算
def cal_two_words_pmi(chars: Dict, pairs: Dict, min_pmi: float = 1e-7, pass_similar: bool = False):
"""
计算pmi, pairs里的key 会尝试所有切分组合,找到最小的pmi切分
:param chars: {"年后":15, "今年":36, ...}
:param pairs: {"今年年后":9, ...}
:param min_pmi: 最小pmi阈值
:return:
"""
filter_ori_pairs = copy.deepcopy(pairs)
log_total_chars = log(sum(chars.values()))
log_total_pairs = log(sum(pairs.values()))
chars = {i: log(j) - log_total_chars for i, j in chars.items()}
pairs = {i: log(j) - log_total_pairs for i, j in pairs.items()}
n_pairs, filter_pairs = {}, {}
for word, value in pairs.items():
pair_mpi = 1e9
# 查找使pmi最小的单词 组合
cut_word_idx = 0
for idx in range(1, len(word)):
if word[:idx] in chars and word[idx:] in chars:
if pair_mpi > value - chars[word[:idx]] - chars[word[idx:]]:
pair_mpi = value - chars[word[:idx]] - chars[word[idx:]]
cut_word_idx = idx
if pair_mpi > min_pmi and cut_word_idx != 0:
if (not pass_similar) or \
(pass_similar and word[:cut_word_idx] not in word[cut_word_idx:] \
and word[cut_word_idx:] not in word[:cut_word_idx] and \
not cal_occr(word[:cut_word_idx], word[cut_word_idx:])):
n_pairs[f"{word[:cut_word_idx]}#{word[cut_word_idx:]}"] = pair_mpi
filter_pairs[f"{word[:cut_word_idx]}#{word[cut_word_idx:]}"] = filter_ori_pairs[word]
# filter_pairs[word] = filter_ori_pairs[word]
return n_pairs, filter_pairs
3 语言模型
3.1 分布式表示
基于统计方法的词嵌入,这些方法都是使用很长的向量来表示一个词语,且词语的“含义”分布在高维度向量的一个或少数几个分量上(稀疏)。这些方法的主要问题在于用于表示词语的向量维度过高且非常稀疏,并且无法很好的表征词语的含义。那么一个理想的词向量应该是什么样呢?
想象一下,我们身处于一个充满词语的空间,这个空间中,相似的词语们组成一个“家族”抱团取暖,它们的距离比较近;不相似的词语身处不同的“家族”,距离较远。如“我”“你”“他”“吴彦祖”这些词的在词空间的距离比较近,“香蕉”和“电脑”在词空间的距离比较远。那么词嵌入其实就是某种将词空间映射到向量空间的方法。
我们希望这些词语映射到一个固定长度的稠密低维度(相对于词表大小而言)向量,且依然保持以上特性,可以使用向量之间的距离来度量词语之间的相似性,这就是
Distributed Representation。基于统计的词嵌入方法产生的向量非常稀疏,词语的含义集中分布在向量的一个或少数几个非零分量上。而“Distributed”其中文意思是“
分布式”,意思是指将词语的语义均匀分布到向量的各个分量上, 每个非零分量都承担其一部分含义。语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率
可以将句子看做单词序列,那么语言模型的目标就是计算 可是这样的方法存在两个致命的缺陷:
- 参数空间过大:条件概率P(wn|w1,w2,..,wn-1)的可能性太多,无法估算,不可能有用;
- 数据稀疏严重:对于非常多词对的组合,在语料库中没有出现,依据最大似然估计得到的概率会是0。
解决方案一:
马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram
假设一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram
一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关。而这些概率参数都是可以通过大规模语料库来计算
实践中用的最多的就是bigram和trigram了,高于四元的用的非常少,由于训练它须要更庞大的语料,并且数据稀疏严重,时间复杂度高,精度却提高的不多
解决方案二:引入平滑技术。平滑技术的思想和目的是将数据集中看到的概率分配一点给未出现的数据(避免概率为0),并且保持总的概率和为1。类似于引入了正则化,对参数进行了约束。这些都是机器学习中解决模型过拟合,提高模型泛化能力的方法。
思考一个问题:
句子1:“A dog is running in the room”
句子2:"A cat is running in the room"
两个句子哪个概率大一些?直觉上来说应该是相似的,但统计语言模型非常受数据集的影响,无法考虑词语与词语的相似度,所以以上两个句子的概率计算结果可能是相差很大的。比如数据集中句子1出现了100次,句子2只出现了1次,那最后的计算结果P(句子1)将远大于P(句子2)。下面介绍的前向神经网络语言模型能比较好地解决这个问题。
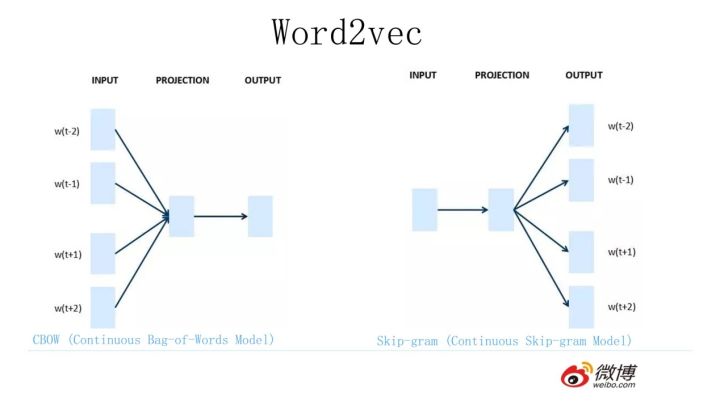
3.2 word2vec
one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding)
目前有两种训练模型(CBOW和Skip-gram),两种加速算法(Negative Sample与Hierarchical Softmax)
Word2Vec包含了两种词训练模型:CBOW模型和Skip-gram模型。
- CBOW:利用上下文的词预测中心词;
- SKIP-GRAM:利用中心词预测上下文的词;
它们的结构仅仅是输入层和输出层不同
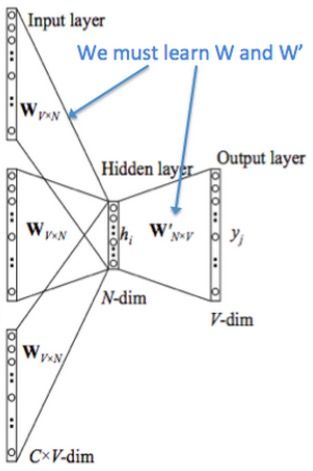
CBOW模型和Skip-gram模型 先来看着这个结构图,用自然语言描述一下CBOW模型的流程:
CBOW模型结构图 >NOTE:花括号内{}为解释内容. > >1. 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C} >2. 所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W} >3. 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1*N. >4. 乘以输出权重矩阵W' {N*V} >5. 得到向量 {1*V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词},概率最大的index所指示的单词为预测出的中间词(target word) >6. 与true label的onehot做比较,误差越小越好 假设我们现在的Corpus是这一个简单的只有四个单词的document: {I drink coffee everyday} 我们选coffee作为中心词,window size设为2 也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。 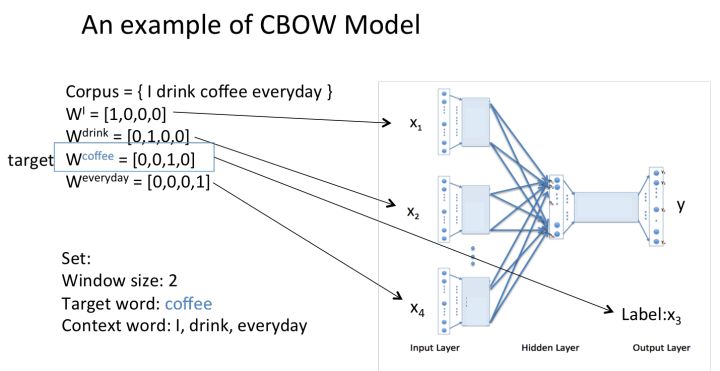 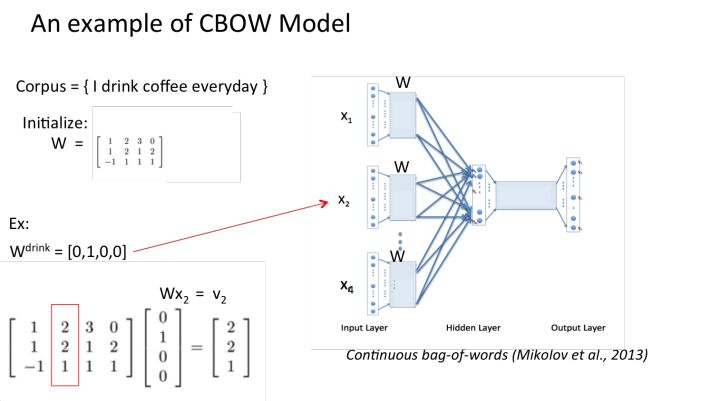 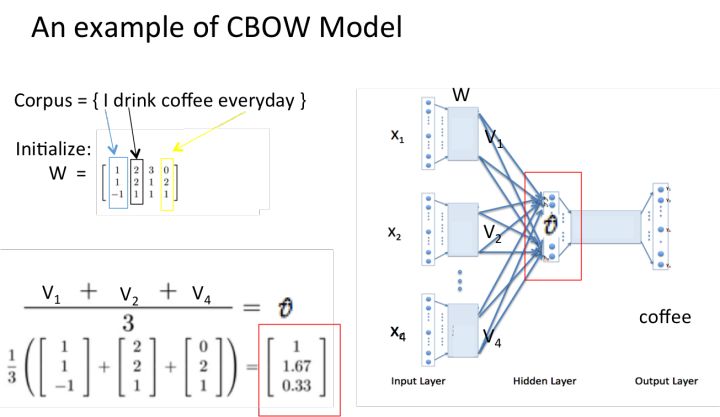 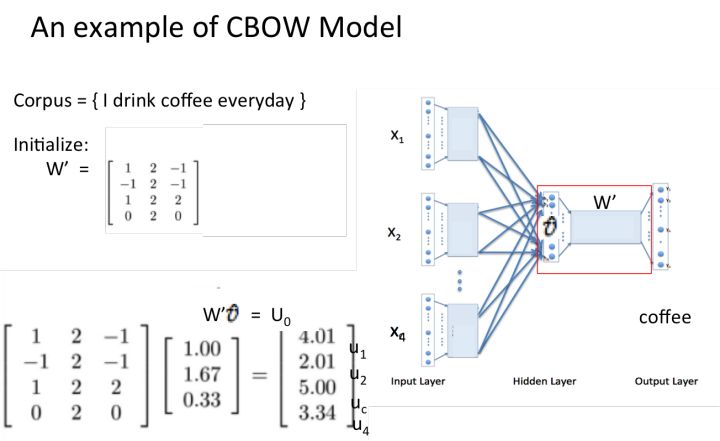  假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,**任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。** **优点** 1. 考虑到词语的上下文,学习到了语义和语法的信息; 2. 得到的词向量维度小,节省存储和计算资源; 3. 通用性强,可以应用到各种*NLP* 任务中; **缺点** 1. 词和向量是一对一的关系,无法解决多义词的问题; 2. word2vec是一种静态的模型,虽然通用性强,但无法真的特定的任务做动态优化; Word2Vec效果图展示


3.3 fasttext
fasttext的模型与CBOW类似,实际上,fasttext的确是由CBOW演变而来的。CBOW预测上下文的中间词,fasttext预测文本标签。与word2vec算法的衍生物相同,稠密词向量也是在训练神经网络的过程中得到的。
3.4 GloVe
GloVe 是斯坦福大学Jeffrey、Richard 等提供的一种词向量表示算法,GloVe 的全称是Global Vectors for Word Representation,是一个基于全局词频统计(count-based & overall staticstics)的词表征(word representation)算法。该算法综合了global matrix factorization(全局矩阵分解) 和 local context window(局部上下文窗口) 两种方法的优点。
优点
- 考虑到词语的上下文、和全局语料库的信息,学习到了语义和语法的信息;
- 得到的词向量维度小,节省存储和计算资源;
- 通用性强,可以应用到各种NLP 任务中;
缺点
- 词和向量是一对一的关系,无法解决多义词的问题;
- glove也是一种静态的模型,虽然通用性强,但无法真的特定的任务做动态优化;

3.5 ELMO
word2vec 和 glove 算法得到的词向量都是静态词向量(静态词向量会把多义词的语义进行融合,训练结束之后不会根据上下文进行改变),静态词向量无法解决多义词的问题(如:“我今天买了7斤苹果” 和 “我今天买了苹果7” 中的 苹果 就是一个多义词)。而ELMO模型进行训练的词向量可以解决多义词的问题。
ELMO 的全称是“ Embedding from Language Models ”,这个名字不能很好的反映出该模型的特点,提出ELMO 的论文题目可以更准确的表达出该算法的特点“ Deep contextualized word representation ”。
该算法的精髓是:用语言模型训练神经网络,在使用word embedding 时,单词已经具备上下文信息,这个时候神经网络可以根据上下文信息对word embedding 进行调整,这样经过调整之后的word embedding 更能表达在这个上下文中的具体含义,这就解决了静态词向量无法表示多义词的问题。
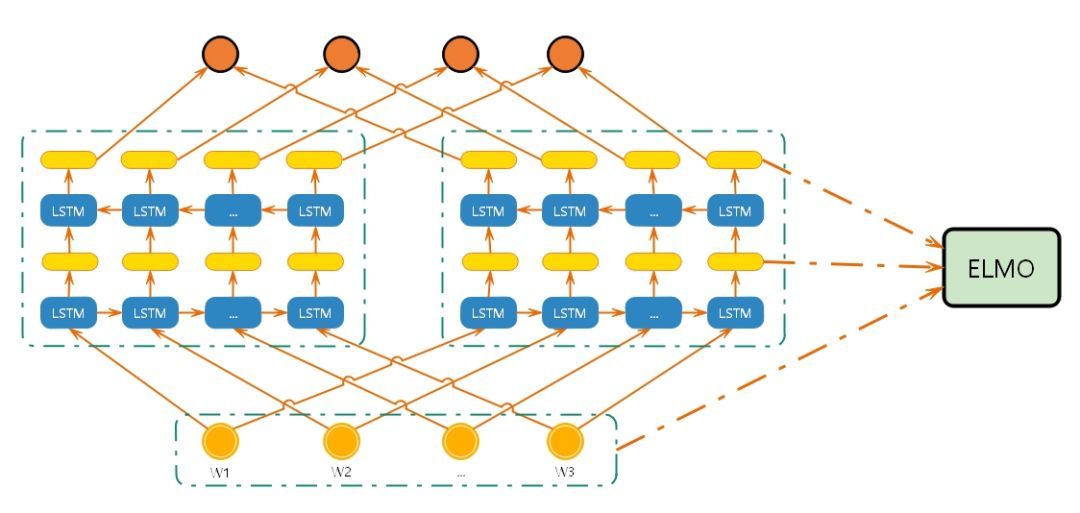
3.5.1 网络模型
3.5.2 过程
- 上图中的结构使用字符级卷积神经网络(convolutional neural network, CNN)来将文本中的词转换成原始词向量(raw word vector) ;
- 将原始词向量输入双向语言模型中第一层 ;
- 前向迭代中包含了该词以及该词之前的一些词汇或语境的信息(即上文);
- 后向迭代中包含了该词以及该词之后的一些词汇或语境的信息(即下文) ;
- 这两种迭代的信息组成了中间词向量(intermediate word vector);
- 中间词向量被输入到模型的下一层 ;
- 最终向量就是原始词向量和两个中间词向量的加权和;
3.5.3 效果
如上图所示:
- 使用glove训练的词向量中,与 play 相近的词大多与体育相关,这是因为语料中与play相关的语料多时体育领域的有关;
- 在使用elmo训练的词向量中,当 play 取 演出 的意思时,与其相近的也是 演出 相近的句子;