
1 最优化理论
2 常见优化方法
前文提到了机器学习领域常用的损失函数以及预测模型的结构。在此基础上,我们需要采用有效的优化手段,通过最小化经验损失函数来求出预测模型里的参数。 最优化这个领域历史悠久,远在机器学习兴起之前,梯度下降法[45]就已经被提出,后续的共扼梯度法6]、坐标下降法[71、牛顿法]、拟牛顿法)、Frank-Wolfe方法[501、Nesterov加速方法51]、内点法2]、对偶方法58]等其他确定性优化算法也被陆续发明。随着大数据的兴起,为了减小优化过程中每次迭代的计算复杂度,人们开始关注随机优化算法,比如随机梯度下降法、随机坐标下降法等。近年来由于深层神经网络变得越来越重要,又有一些专门针对深层神经网络的优化算法被发明。由于我们将会用第4章、第5章两章篇幅对优化算法进行详细的介绍,因此本节就不再赘述,而是仅仅简单梳理一下优化算法的发展脉络。表2.2总结了典型的优化方法。
一阶算法 二阶算法 确定性算法 梯度下降法
投影次梯度下降
近端梯度下降法
Frank-Wolfe算法
Nesterov加速方法
坐标下降法
对偶坐标上升法牛顿法
拟牛顿法随机算法 随机梯度下降法
随机坐标下降法
随机对偶坐标上升法
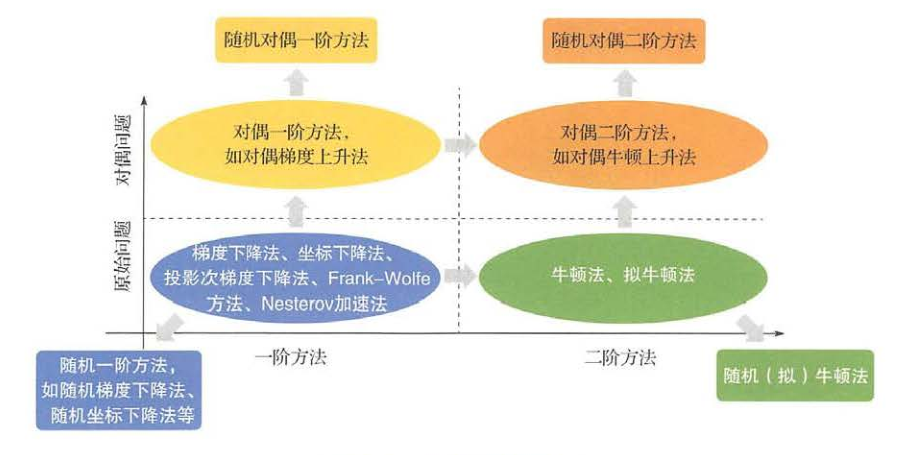
随机方差减小梯度法随机拟牛顿法 确定性优化方法从算法所使用的信息的角度可以分为一阶方法和二阶方法,从解问题的角度可以分为原始方法和对偶方法。所谓一阶方法指的是在优化过程中只利用了目 标函数的一阶导数信息,而二阶方法则要利用到目标函数的二阶导数(例如海森矩阵)。 所谓原始方法指的是针对原始问题描述中的变量进行优化,而对偶方法则是先通过对偶变换把原始问题转换成对偶问题,再针对对偶变量进行优化。 随着大数据的出现,确定性优化方法的效率成为瓶颈。于是,人们基于确定性优化方法设计了各种随机优化方法。这些算法的基本思想是每次迭代不使用全部训练样本或全部特征维度进行优化,而是随机抽样一个/一组样本,或一个/一组特征,再利用这些抽样的信息来计算一阶或二阶导数,对目标函数进行优化。在很多情况下,可以证明随机优化算法可以看作对原确定性算法的无偏意义上的实现,因此有一定的理论保障。但是,有时随机采样会带来比较大的方差,这就需要我们使用一些新的技术手段去控制方差(例如SVRG方法[5]等)。 上面提到的绝大部分优化算法在求解凸优化问题时的理论性质是比较清楚的,但是近年来随着深层神经网络变得越来越重要,非凸优化的问题逐渐浮出水面并受到大家的广泛重视。以上算法在非凸优化的情况下,还存在很大的理论空白。例如: ·这些优化算法的收敛性质在非凸问题上能否得以保持?与其在凸问题上的收敛速度有何不同? ·非凸问题有很多局部极值点和鞍点,如何通过初始化或者其他手段来逃离鞍点并且使最终的优化结果收敛到较好的极值点(相应的目标函数值低、鲁棒性强 或泛化性能好)? ·已有的优化算法中哪些更适合用来训练神经网络?能否设计新的适用于神经网络的优化方法? 为了解决以上问题,尤其是加速神经网络训练的收敛速度,近年来人们提出了一系列针对神经网络优化的算法,例如:带冲量的随机梯度下降法[5]、Nesterov加速方法[581、AdaGrad 561、RMSProp 571、AdaDeltal58]、Adam1591、AMSGrad60l、等级优化算法[0]以及基于嫡的随机梯度下降法]等。从某种意义上讲,深度学习开启了非凸优化的大门,给拥有几百年历史的优化领域注入了新的活力。我们相信将来会有更多、更好的优化算法被提出,从而更快、更优地对复杂的非凸优化问题进行求解。
>