1 概率论基础
2 概率空间
说到概率,通常是指一个具有不确定性的
event发生的可能性,例如,下周二下雨的概率。因此,为了正式地讨论概率论,我们首先要明确什么是可能事件。 正规说来,一个
probability space是由三元组定义: -为样本空间
-(0的幂集)为(可度量的)事件空间
-为将事件映射到真值区间的概率度量(概率分布),可以将看作概率函数
注:的幂集--是的所有子集的集合,符号:,个元素,个元素。
假设给定样本空间,则对于事件空间来说:
-包含本身和
-对于并集闭合,例如:如果,则
-对于补集闭合,例如:如果,则
Example1: 假如我们投掷一个(6面)骰子,那么可能的样本空间。
我们可能感兴趣的事件是骰子点数是奇数还是偶数,
那么这种情况下事件空间就是. 可以看到样本空间为有限集时,就像上一个例子,我们通常令事件空间为。这种策略并不完全通用,但是在实际使用中通常是有效的。
然而,当样本空间为无限集时,我们需要仔细定义事件空间。给定一个事件空间,概率函数需要满足几个公理:
-(非负)对于所有,
-P(F)=1,事件空间的概率值为1
-(互斥事件的加法法则)对于所有和,
Example2: 回到掷骰子的例子,假设事件空间为,进一步地,定义上的概率函数为: 那么这种概率分布可以完整定义任意给出事件的发生概率(通过可加性公理)。
例如,投掷点数为偶数的概率为:
因为任意事件(此处指样本空间内的投掷出各点数)之间都没有交集
3 随机变量
随机变量在概率论中扮演着一个重要角色。
最重要的一个事实是,随机变量并不是变量,它们实际上是将(样本空间中的)结果映射到真值的函数。
我们通常用一个大写字母来表示随机变量。 Example3: 还是以掷骰子为例,
为取决于投掷结果的随机变量,的一个自然选择是将 映射到值 。
例如,将事件“投掷1点“映射到值1。我们也可以选择一些特别的映射,例如,我们有一个随机变量--将所有的结果映射到0,这就是一个很无聊的函数。或者随机变量--当 为奇数时,将结果映射到;当 为偶数时,将结果 映射到 。
从某种意义上说,随机变量可以将事件空间的形式概念抽象出来,通过定义随机变量来采集相关事件。举个例子,考虑Example1中投掷点数为奇/偶的事件空间。
我们其实可以定义一个随机变量,当结果 为奇数时取值为1,否则随机变量取值为0。
这种二元算计变量在实际中非常常见,通常以指示变量为人所知,它是因用于指示某一特定事件是否发生而得名。
所以为什么我们要引进事件空间?就是因为当一个人在学习概率论(更严格来说)通过计量理论来学习时,样本空间和事件空间的区别非常重要。
随机变量让我们能提供一种对于概率论的更加统一的处理方式。取值为的随机变量的概率可以记为: 或
4 概率分布、联合分布和边缘分布
变量的分布,正式来说,它是指一个随机变量取某一特定值的概率,
Example4: 假设在投掷一个骰子的样本空间上定义一个随机变量,如果骰子是均匀的,则的分布为:。
注意,尽管这个例子和Example2类似,但是它们有着不同的语义。
Example2中定义的概率分布是对于事件而言,而这个例子中是随机变量的概率分布。 我们用来表示随机变量的概率分布。 有时候,我们会同时讨论大于一个变量的概率分布,这种概率分布称为
联合分布,因为此事的概率是由所涉及到的所有变量共同决定的。 Example5: 在投掷一个骰子的样本空间上定义一个随机变量。定义一个指示变量,当抛硬币结果为正面朝上时取1,反面朝上时取 0。
假设骰子和硬币都是均匀的,则和的联合分布如下:
像前面一样,我们可以用或来表示取值为且取值为时的概率。
用来表示它们的联合分布。
假定有一个随机变量和的联合分布,我们就能讨论或的边缘分布。
边缘分布是指一个随机变量对于其自身的概率分布。为了得到 一个随机变量的边缘分布,我们将该分布中的所有其它变量相加,准确来说,就是: 之所以取名为边缘分布,是因为如果我们将一个联合分布的一列(或一行)的输入相加,将结果写在它的最后(也就是边缘),那么该结果就是这个随机变量取该值时的概率。
当然,这种思路仅在联合分布涉及两个变量时有帮助。
5 条件分布
条件分布为概率论中用于探讨不确定性的关键工具之一。
它明确了在另一随机变量已知的情况下(或者更通俗来说,当已知某事件为真 时)的某一随机变量的分布。 正式地,给定时,的条件概率定义为: 注意,当的概率为0时,上式不成立。 Example6: 假设我们已知一个骰子投出的点数为奇数,想要知道投出的点数为"1"的概率。
令为代表点数的随机变量,为指示变量,当点数为奇数时取值为1,那么我们期望的概率可以写为: 条件概率的思想可以自然地扩展到一个随机变量的分布是以多个变量为条件时,即: 我们用来表示当时随机变量的分布,也可以用来表示的一系列分布,其中每一个都对应不同的可以取的值。
6 条件独立
在概率论中,独立性是指随机变量的分布不因知道其它随机变量的值而改变。
在机器学习中,我们通常都会对数据做这样的假设。例如,我们会假设训练样本是从某一底层空间独立提取;并且假设样例的标签独立于样例的特性。 从数学角度来说,随机变量独立于,当
(注意,上式没有标明,的取值,也就是说该公式对任意,可能的取值均成立)
利用等式(2),很容易可以证明如果对独立,那么也独立于。当和相互独立时,记为。
对于随机变量和的独立性,有一个等价的数学公式: 我们有时也会讨论条件独立,就是当我们当我们知道一个随机变量(或者更一般地,一组随机变量)的值时,那么其它随机变量之间相互独立。
正式地,我 们说"给定,和条件独立",如果: 或者等价的: 机器学习(Andrew Ng)的课中会有一个朴素贝叶斯假设就是条件独立的一个例子。
该学习算法对内容做出假设,用未分辨电子邮件是否为垃圾邮件。假设无论邮件是否为垃圾邮件,单词出现在邮件中的概率条件独立于单词。
很明显这个假设不是不失一般性的,因为某些单词几乎总是同时出现。然而最终结果是,这个简单的假设对结果的影响并不大,且无论如何都可以让我们快速判别垃圾邮件。
7 链式法则和贝叶斯定理
我们现在给出两个与联合分布和条件分布相关的,基础但是重要的可操作定理。
第一个叫做
链式法则,它可以看做等式(2)对于多变量的一般形式。 定理1(链式法则): 链式法则通常用于计算多个随机变量的联合概率,特别是在变量之间相互为(条件)独立时会非常有用。注意,在使用链式法则时,我们可以选择展开随机变量的顺序;选择正确的顺序通常可以让概率的计算变得更加简单。
第二个要介绍的是
贝叶斯定理。利用贝叶斯定理,我们可以通过条件概率算出,从某种意义上说就是交换条件。
它也可以通过等式(2)推导出。 定理2(
贝叶斯定理): 记得,如果没有给出,我们可以用等式(1)找到它: 这种等式(1)的应用有时也被称为全概率公式,贝叶斯定理可以推广到多个随机变量的情况。在有疑问的时候,我们都可以参考条件概率的定义方式,弄清楚其细节。 Example7: 考虑以下的条件概率:和
8 离散分布和连续分布
离散分布:概率质量函数: 就一个离散分布而言,我们是指这种基本分布的随机变量只能取有限多个不同的值(或者样本空间有限)。 在定义一个离散分布时,我们可以简单地列举出随机变量取每一个可能值的概率。这种列举方式称为概率质量函数(probability mass function[PMF]),因为它将(总概率的)每一个单元块分开,并将它们和随机变量可以取的不同值对应起来。这个可以类似的扩展到联合分布和条件分布。
连续分布:概率密度函数: 对连续分布而言,我们是指这种基本分布的随机变量能取无限多个不同值(或者说样本空间是无限的)。 连续分布相比离散分布来说是一种更加需要揣摩的情况,因为如果我们将每一个值取非零质量数,那么总质量相加就会是一个无限值,这样就不符合总概率相加等于1的要求。 在定义一个连续分布时,我们会使用
概率密度函数(probability density function[PDF])。概率密度函数f是一个非负,可积(分)的函数,类似于: 符合PDF 的随机变量的概率分布可以用如下公式计算: 注意,特别地,默认连续分布的随机变量取任意单一值的概率为零。
Example8:(均匀分布)假设随机变量在上均匀分布,则对应的PDF为: 我们可以确定为1,因此为PDF。计算的概率小于. 更一般地,假设在上均匀分布,那么PDF即为: 有时我们也会讨论累积分布函数,这种函数给出了随机变量在小于某一值的概率。
累积分布函数和基本概率密度函数的关系如下: 因此,(就不定积分而言)。要将连续分布的定义扩展到联合分布,需要把概率密度函数扩展为多个参数,即: 将条件分布扩展到连续随机变量时,会遇到一个问题——连续随机变量在单个值上的概率为0,因此等式(2)不成立,因为分母等于0。
为了定义连续变量的条件分布,要令为和的联合分布。
通过分析,我们能看到基于分布的PDF 为: 即如果直接用的话,可能在分母为零,所以用,通过积分间接得到,例如:
9 期望
我们对随机变量做的最常见的操作之一就是计算它的期望,也就是它的平均值(mean),期望值(expected value),或一阶矩(first moment)。
随机变量的期望记为,计算公式:
Example9: 令为投掷一个均匀散子的结果,则的期望为: 有时我们可能会对计算随机变量的某一函数f的期望值感兴趣,再次重申,随机变量本身也是一个函数,因此最简单的考虑方法是定义一个新的随机变量,然后计算的期望。
当使用指示变量时,一个有用的判别方式是:
此处可以脑补还有一个取值为0,即
当遇到随机变量的和时,一个最重要的规则之一是线性期望(linearity of expectations)。 定理3(
线性期望): 令为(可能是独立的)随机变量: 期望为线性函数。期望的线性非常强大,因为它对于变量是否独立没有限利。当我们对随机变显的结果进行处理时,通常没什么可说的,但是,当随机变量相互独立时有
定理4:令和为相互独立的随机变量,则:
10 方差
一个随机变显的方差描述的是它的商散程度,也就是该变量离其期望值的距离。
一个实随机变量的方差也称为它的二阶矩或二阶中心动差,恰巧也是它的二阶累积量,方差的算术平方根称为该随机变量的标准差。
方差的定义: 随机变量的方差通常记为,给它取平方的原因是因为我们通常想要找到,也就是
标准差。方差和标准差可以用公式相关联。
为了找到随机变量的方差,通常用以下替代公式更简单: 注意,不同于期望|方差不是关于随机变量的线性函数,事实上,我们可以证明的方差为: 如果随机变量和相互独立,那么: 有时我们也会讨论两个随机变量的协方差,它可以用来威量两个随机变量的相关性,定义如下:
11 伯努利、泊松、高斯分布
伯努利(Bernoulli)分布: 伯努利分布是最基础的概率分布之一,一个服从伯努利分布的随机变量有两种取值,它能通过一个变量未表示其概率,为了方便我们令为。它通常用于预测试验是否成功。有时将一个服从伯努利分布的变量的概率分布按如下表示会很有用: 一个伯努利分布起作用的例子是Lecture Notes1中的分类任务。
为了给这个任务开发一个逻辑回归算法,对于特征来说,我们假设标签遵循伯努利概率分布。
泊松(Poisson)分布: 泊松分布是一种非常有用的概率分布,通常用于处理事件发生次数的概率分布。在给定一个事件发生的固定平均概率,并且在该段事件内事件发生相互独立时,它可以用来度量单位间内事件发生的次数,它包含一个参数——平均事件发生率入。
泊松分布的概率质量函数为: 服从泊松分布的随机变量的平均值为,其方差也为,
高斯(Gaussian)分布: 高斯分布也就是正态分布,是概率论中最”通用”的概率分布之一,并且在很多环境中都有出现。例如,在试验数量很大时用在二项分布的近似处理中,或者在平均事件发生率很高时用于泊松分布。
它还和大数定理相关。对于很多问题来说,我们还会经常假设系统中的噪声服从高斯分布。
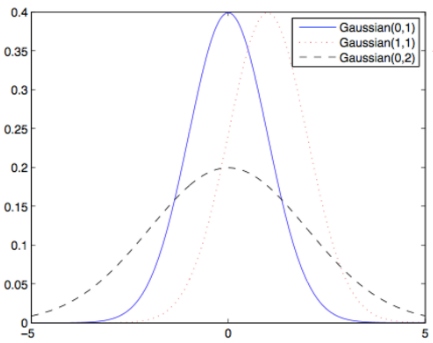
上图为不同期望和方差下的高斯分布。 高斯分布由两个参数决定:期望和方差。
其概率密度函数为: 为了更好的感受概率分布随着期望和方差的改变,在上图中绘利了三种不同的高斯分布。 一个维多变量高斯分布用参数表示,其中,为上的期望矢量,为上的协方差矩阵,
也就是说且。
其概率密度函数由输入的矢量定义: (我们标记矩阵的行列式为,其转置为)
12 Jenson不等式
有时我们会计算一个函数对某个随机变量的期望,通常我们只需要一个区间而不是具体的某个值。在这种情况下,如果该函数是凸函数或 者凹函数,通过Jenson不等式,我们可以通过计算随机变量自身期望处的函数值来获得一个区间。
(上图为Jenson不等式图示)
定理5(Jenson不等式): 令为一个随机变量,为凸函数,那么: 如果为凹函数,那么: 尽管我们可以用代数表示Jenson不等式,但是通过一张图更容易理解。
上图中的函数为一个凹函数,我们可以看到该函数任意两点之间的直线都在函数的上方,也就是说,如果一个随机变量只能取两个值,那么Jenson不等式成立。这个也可以比较直接地推广到一般随机变量。