
1 评估指标
2 准确率(Accuracy)
准确率是指分类正确的样本占总样本个数的比例,即 其中为被正确分类的样本个数,为总样本的个数。 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。 所以,当不同类别的样本比例非常不均衡时, 占比大的类别往往成为影响准确率的最主要因素。
错误率是指分类错误的样本数占样本总数的比例,即
3 精确度(Precision)
精确率是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。召回率是指分类正确的正样本个数占真正的正样本个数的比例。 在排序问题中,通常没有一个确定的闽值把得到的结果直接判定为正样本或负样本,而是采用返回结果的值和值来衡量排序模型的性能,即认为模型返回的的结果就是模型判定的正样本,然后计算前个位置上的准确率和前个位置上的召回率。
相关(Relevant),正类 无关(NonRelevant),负类 被检索到
(Retrieved)true positives( TP正类判定为正类,例子中就是正确的判定“这位是女生")false positives( FP负类判定为正类,“存伪",例子中就是分明是男生却判断为女生,当下伪娘横行,这个错常有人犯)未被检索到
(not Retrieved)false negatives( FN正类判定为负类,“去真”,例子中就是,分明是女生,这哥们却判断为男生--梁山伯同学犯的错就是这个)true negatives( TN负类判定为负类,也就是一个男生被判断为男生, 像我这样的纯爷们一准儿就会在此处)根据这四种数据,有四个比较重要的比率:
灵敏度表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力:特效度表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力:精确率(precision)计算的是所有“正确被检索的结果(TP)“占所有“实际被检索到的"的比例: 在例子中就是希望知道此君得到的所有人中,正确的人(也就是女生)占有的比例,所以其也就是40%().
4 召回率(Recall)
召回率(recall)的公式是,它计算的是所有“正确被检索的结果(TP)“占所有“应该检索到的结果"的比例. 在例子中就是希望知道此君得到的女生占本班中所有女生的比例,所以其也就是100%()
5 均方根误差(RMSE)
概念: RMSE经常被用来衡量回归模型的好坏,计算公式为 其中, 是第个样本点的真实值, 是第个样本点的预测值,是样本点的个数。 一般情况下,E能够很好地反映回归模型预测值与真实值的概念偏离程度。
缺点: 但在实际问题中,如果存在个别偏离程度非常大的离群点(Outlier)时,即使离群点数量非常少,也会让指标变得很差。 回到问题中来,模型在95%的时间区间内的预测误差都小于1%, 这说明在大部分时间区间内,模型的预测效果都是非常优秀的。然而却一直很差,这很可能是由于在其他的5%时间区间内存在非常严重的离群点。事实上,在流量预估这个问题中,噪声点确实是很容易产生的,比如流量特别小的美剧、刚上映的美剧或者刚获奖的美剧,甚至一些相关社交媒体突发事件带来的流量,都可能会造成离群点。
解决: 可以从三个角度来思考。第一, 如果我们认定这些离群点是“噪声点”的话,就需要在数据预处理的阶段把这些噪声点过滤掉。
第二,如果不认为这些离群点是“噪声点”的 话,就需要进一步提高模型的预测能力,将离群点产生的机制建模进去(这是一个宏大的话题,这里就不展开讨论了)。
第三,可以找一个更合适的指标来评估该模型。
关于评估指标,其实是存在比的鲁棒性更好的指标,比如
平均绝对百分比误差(Mean Absolute Percent Error,MAPE),它定义为 相比,相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。
6 F1得分
除此之外,和曲线也能综合地反映一个排序模型的性能。
是精准率和召回率的调和平均值,它定义为
7 P-R曲线
为了综合评估一个排序模型的好坏,不仅要看模型在不同下的和,而且最好绘制出模型的(Precision-Recall)曲线。
曲线的
横轴是召回率,纵轴是精确率。对于一个排序模型来说, 其曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
整条曲线是通过将阈值从高到低移动而生成的。
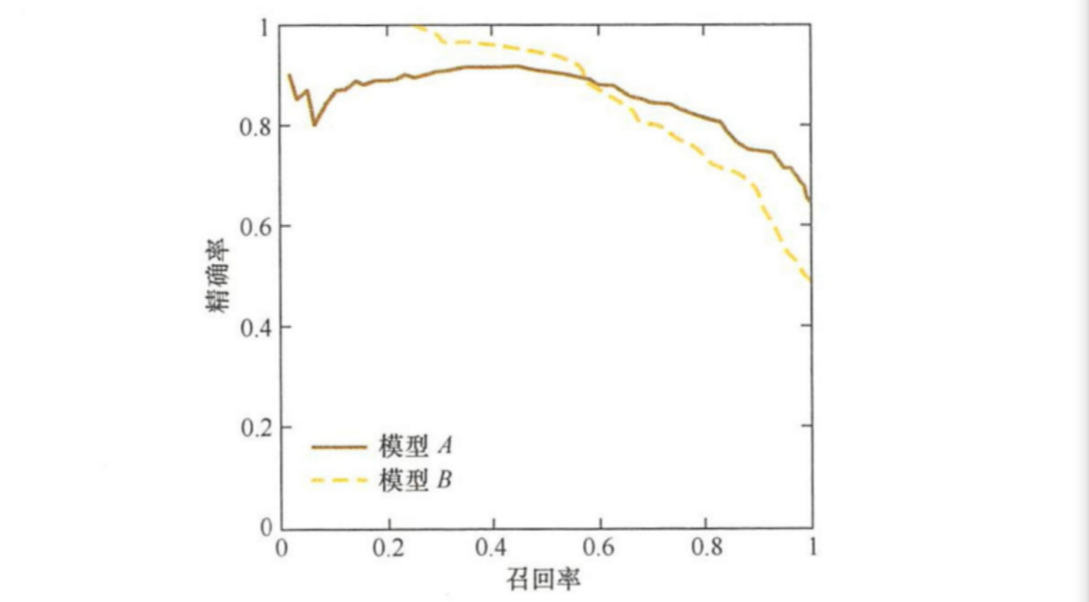
图是曲线样例图,其中实线代表模型的曲线,虚线代表模型的曲线。
原点附近代表当阀值最大时模型的精确率和召回率。
8 ROC曲线
8.1 ROC曲线概念
ROC曲线是Receiver Operating Characteristic Curve的简称, 中文名为“受试者工作特征曲线”。曲线源于军事领域,而后在医学领域应用甚广,“受试者工作特征曲线”这一名称也正是来自医学领域。
曲线的
横坐标为假阳性率(False Positive Rate, );纵坐标为真阳性率(True Positive Rate, )。和的计算方法分别为 式中,是真实的正样本的数量,是真实的负样本的数量,是个正样本中被分类器预测为正样本的个数,是个负样本中被分类器预测为正样本的个数。假设有10位疑似癌症患者,其中有3位很不幸确实患了癌症(),另外7位不是癌症患者()。医院对这10位疑似患者做了诊断,诊断出3位癌症患者,其中有2位确实是真正的患者()。
那么真阳性率。对于7位非癌症患者来说,有一位很不幸被误诊为癌症患者(),那么假阳性率。
对于“该医院”这个分类器来说,这组分类结果就对应ROC曲线上的一个点()。 事实上,ROC曲线是通过
不断移动分类器的“截断点”来生成曲线上的一组关键点的。通过下面的例子进一步来解释“截断点”的 概念。 在二值分类问题中,模型的输出一般都是预测样本为正例的概率。
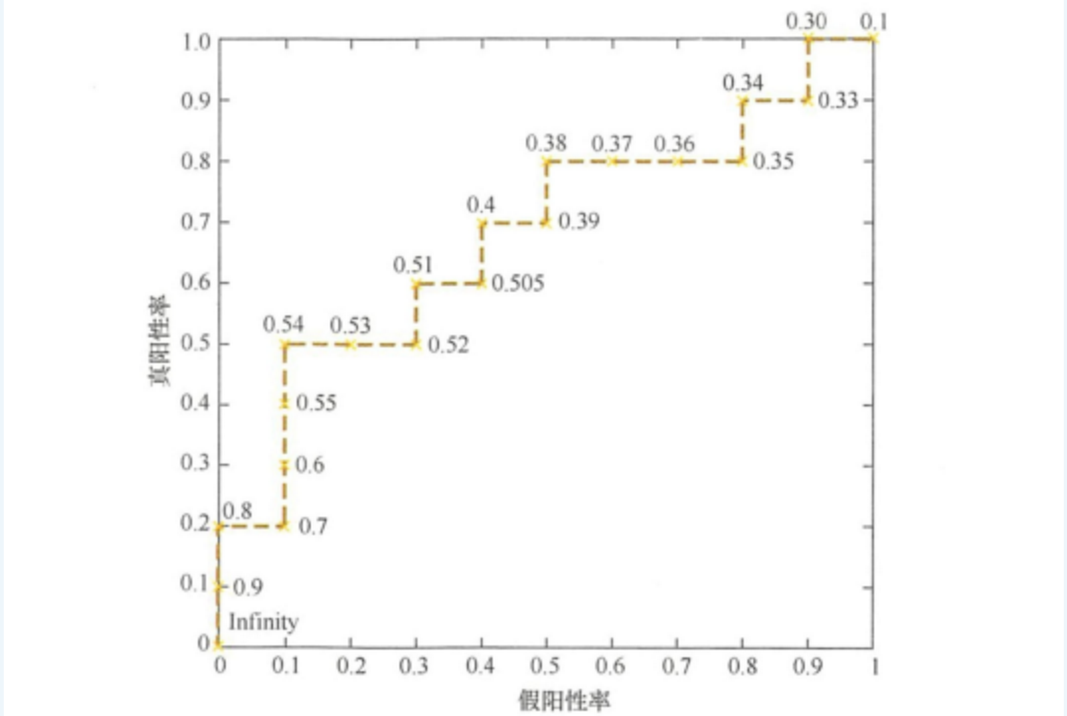
样本序号 真实标签 模型输出概率 样本序号 真实标签 模型输出概率 1 p 0.9 11 p 0.4 2 p 0.8 12 n 0.39 3 n 0.7 13 p 0.38 4 p 0.6 14 n 0.37 5 p 0.55 15 n 0.36 6 p 0.54 16 n 0.35 7 n 0.53 17 p 0.34 8 n 0.52 18 n 0.33 9 p 0.51 19 p 0.30 10 n 0.505 20 n 0.1 假设测试集中有20个样本,表2.1是模型的输出结果。样本按照预测概率从高到低排序。在输出最终的正例、负例之前,我们需要指定一个 阈值,预测概率大于该阀值的样本会被判为正例,小于该阈值的样本则会被判为负例。
比如,指定阀值为0.9,那么只有第一个样本会被预测为正例,其他全部都是负例。
上面所说的“截断点”指的就是区分正 预测结果的阈值。 通过动态地调整截断点,从最高的得分开始(实际上是从正无穷开始,对应着曲线的零点),逐渐调整到最低得分,每一个截断点都会对应一个和,在图上绘制出每个截断点对应的位置, 再连接所有点就得到最终的曲线。
8.2 绘制ROC曲线
就本例来说,当截断点选择为正无穷时,模型把全部样本预测为负例,那么和必然都为0,和也都为0,因此曲线的第 一个点的坐标就是。
当把截断点调整为0.9时,模型预测1号样本为正样本,并且该样本确实是正样本,因此,20个样本中, 所有正例数量为,故;
这里没有预测错的正样本, 即,负样本总数,故,对应ROC曲线上的点。
依次调整截断点,直到画出全部的关键点,再连接关键点即得到最终的曲线,如下图所示。
其实,还有一种更直观地绘制曲线的方法。
首先,根据样本 标签统计出正负样本的数量,假设正样本数量为,负样本数量为;
接下来,把横轴的刻度间隔设置为,纵轴的刻度间隔设置为;
再根据模型输出的预测概率对样本进行排序(从高到低);
依次遍历样 本,同时从零点开始绘制曲线,每遇到一个正样本就沿纵轴方向绘制一个刻度间隔的曲线,每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线,直到遍历完所有样本,曲线最终停在这个点, 整个曲线绘制完成。
8.3 ROC和P-R曲线
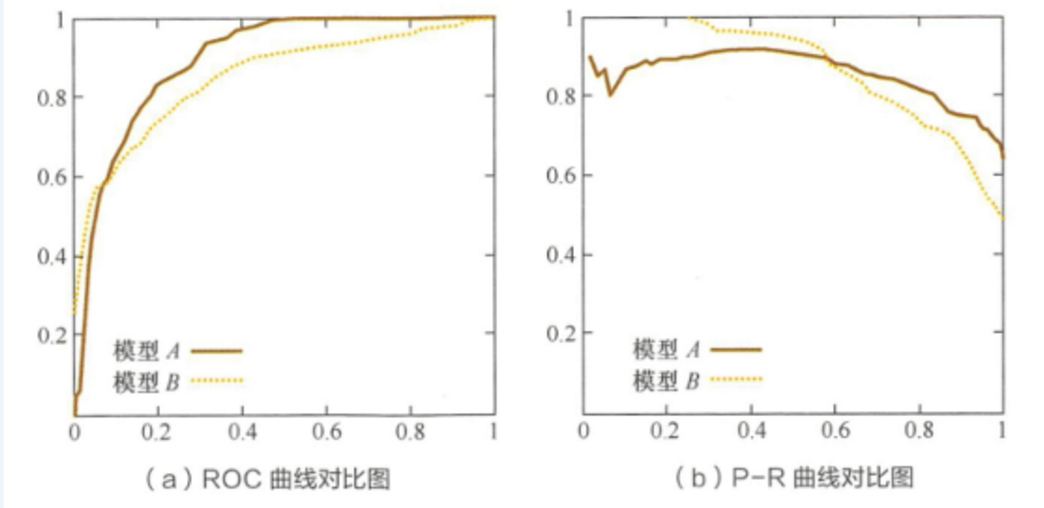
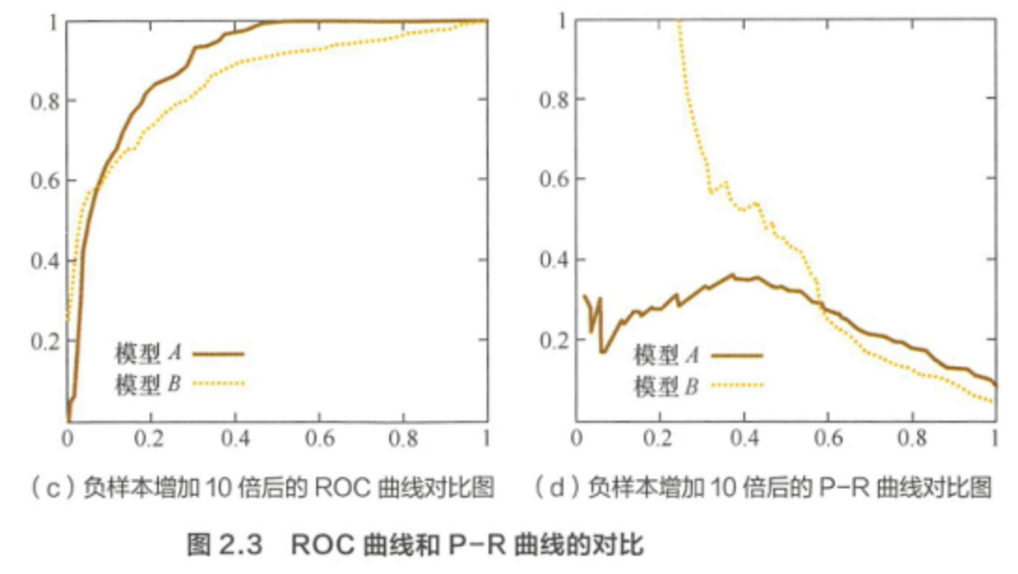
可以看出,曲线发生了明显的变化,而曲线形状基本不变。
这个特点让曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能。
这有什么实际意义呢?在很多实际问题中,正负样本数量往往很不均衡。比如,计算广告领域经常涉及转化率模型,正样本的数量往往是负样本数量的1/1000甚至1/10000。
若选择不同的测试集,曲线的变化就会非常大,而曲线则能够更加稳定地反映模型本身的好坏。
所以,曲线的适用场景更多,被广泛用于
排序、推荐、广告等领域。但需要注意的是,选择曲线还是曲线是因实际问题而异的,如果研究者希望更多地看到模型在特定数据集上的表现,曲线则能够更直观地反映其性能。
9 AUC曲线
顾名思义,指的是曲线下的面积大小,该值能够量化地反映基于曲线衡量出的模型性能。
计算值只需要沿着横轴做积分就可以了。
由于曲线一般都处于这条直线的上方(如果不是的话,只要把模型预测的概率反转成就可以得到一个更好的分类器),所以的取值一般在之间。
越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
10 聚类指标
一个好的聚类方法可以产生高品质簇,是的簇内相似度高,簇间相似度低。一般来说,评估聚类质量有两个标准,内部质量评价指标和外部评价指标。
3.1.9.1 内部质量评价标准
内部评价指标是利用数据集的属性特征来评价聚类算法的优劣。通过计算总体的相似度,簇间平均相似度或簇内平均相似度来评价聚类质量。评价聚类效果的高低通常使用聚类的有效性指标,所以目前的检验聚类的有效性指标主要是通过簇间距离和簇内距离来衡量。这类指标常用的有CH(Calinski-Harabasz)指标等
CH指标: 其中表示类间距离差矩阵的迹,表示类内差矩阵的迹,是整个数据集的均值,是第个簇的均值,代表聚类的个数, 代表当前的类。值越大,聚类效果越好,主要计算簇间距离与簇内距离的比值
簇的凝聚度: 簇内点对的平均距离反映了簇的凝聚度,一般使用组内误差平方(SSE)表示
簇的邻近度:簇的邻近度用组间平方和(SSB)表示,即簇的质心到簇内所有数据点的总平均值的距离的平方和
3.1.9.2 外部质量评价标准
外部质量评价指标是基于已知分类标签数据集进行评价的,这样可以将原有标签数据与聚类输出结果进行对比。
外部质量评价指标的理想聚类结果是:具有不同类标签的数据聚合到不同的簇中,具有相同类标签的数据聚合相同的簇中。外部质量评价准则通常使用熵,纯度等指标进行度量。
熵:簇内包含单个类对象的一种度量。对于每一个簇,首先计算数据的类分布,即对于簇,计算簇的成员属于类的概率 其中表示簇中所有对象的个数,而是簇中类的对象个数。使用类分布,用标准公式: 计算每个簇的熵,其中是类个数。簇集合的总熵用每个簇的熵的加权和计算即: 其中是簇的个数,而是簇内数据点的总和
纯度:簇内包含单个类对象的另外一种度量。簇的纯度为,而聚类总纯度为: 08 聚类算法 - 聚类算法的衡量指标
11 回归指标
SSE(和方差、误差平方和):The sum of squares dueto error MSE(均方差、方差):Meansquared error RMSE(均方根、标准差):Root mean squared error R-square(确定系数):Coefficientof determination Adjusted R-square:Degree-of-freedomadjusted coefficient of determination
SSE:R-square:Adjusted R-square: 其中是样本数量;是特征数量;是决定系数,该指标消除了样本数量和特征数量的影响,做到了真正的0~1,越大越好。
AIC赤池信息准则: 估计模型拟合数据的优良性,AIC值越小说明模型拟合得越好