
1 spark环境搭建
1.1 版本总览
(ray37) [root@Slave03 huangyc]# java -version
java version "1.8.0_281"
(ray37) [root@Slave03 huangyc]# hadoop version
Hadoop 3.2.1
Compiled with protoc 2.5.0
(ray37) [root@Slave03 huangyc]# scala -version
Scala code runner version 2.12.15 -- Copyright 2002-2021, LAMP/EPFL and Lightbend, Inc.
(ray37) [root@Slave03 huangyc]# sh /usr/spark-3.0/bin/spark-shell
Spark context Web UI available at http://Slave03:4040
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.3
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_281)
百度网盘下载 提取码:
7g8v
1.2 scala
下载并安装scala
- 下载 scala-2.12
- 安装
rpm -ivh scala-2.12.15.rpm - 查看scala版本
scala -version
配置环境
查询包中文件安装位置 -l:
rpm -ql 包名
编辑
/etc/profile,文件末尾添加配置# 配置scala环境变量 export SCALA_HOME=/usr/share/scala/bin export PATH=$PATH:$SCALA_HOME
执行source /etc/profile令其生效
其他节点同样配置即可
1.3 免密登录
1.3.1 修改主机名(非必须)
查看主机名用
hostname修改主机名/etc/hostname修改后重启服务器reboot配置host文件
vi /etc/hosts
192.168.123.21 Slave00
192.168.123.23 Slave02
192.168.123.24 Slave03
/etc/init.d/network restart
1.3.2 生成秘钥对
使用
RSA类型的加密类型来创建密钥对
# 生成秘钥(-f换名字好像不行)
ssh-keygen -t rsa
# 配置本机免密
cat id_rsa.pub>>authorized_keys
- -f 参数表示指定密钥对生成位置与名称
- 密钥对通常放在
~/.ssh目录下 - 回车即可创建密钥对,需要输入密码如果不需要为密钥对进行加密,那么可以一路回车
- 有需要清空文件的可以执行
truncate -s 0 authorized_keys
创建成功之后,可以看到 .ssh 目录下多了两个文件,分别是:
- id_key:密钥对的私钥,通常放在客户端
- id_rsa.pub:密钥对中的公钥,通常放在服务端
1.3.3 秘钥上传服务器
文件权限
sudo chmod -R 700 ~/.ssh
sudo chmod -R 600 ~/.ssh/authorized_keys
将your_key.pub 公钥文件上传至需要连接的服务器
# 方式一:追加在其他服务器文件末尾(本机不需要)
cat ~/.ssh/id_rsa.pub | ssh root@192.168.123.21 "cat - >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh root@192.168.123.23 "cat - >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh root@192.168.123.24 "cat - >> ~/.ssh/authorized_keys"
# 方式二
ssh-copy-id -i ~/.ssh/id_key.pub root@192.168.123.21
ssh-copy-id -i ~/.ssh/id_key.pub root@192.168.123.23
ssh-copy-id -i ~/.ssh/id_key.pub root@192.168.123.24
- -i 参数表示使用指定的密钥,-p参数表示指定端口,ssh 的默认端口是 22
1.3.4 公钥查看
本地的公钥文件上传在服务器的.ssh/authorized_keys 文件中
cat ~/.ssh/authorized_keys
1.3.5 免密检测
ssh Slaver00
ssh Slaver02
ssh Slaver03
1.4 hadoop
1.4.1 新建用户(非必须)
新建hadoop用户
useradd -m hadoop -s /bin/bash
修改hadoop用户密码
passwd hadoop
切换用户
su hadoop
新建文件夹
mkdir /home/hadoop/apps
mkdir /home/hadoop/data
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
关闭selinux
vim /etc/sysconfig/selinux
修改SELINUX=enforcing为SELINUX=disabled
1.4.2 安装
下载并解压hadoop到
/usr/hadoop-3.2.0
下载 hadoop-3.2.0,解压到
/usr/hadoop-3.2.0配置环境变量
export HADOOP_HOME=/usr/hadoop-3.2.0 export PATH=$PATH:$HADOOP_HOME执行
source /etc/profile令其生效查看hadoop版本,
hadoop version
1.4.3 配置文件
Hadoop配置文件的配置,需要配置的文件有几个分别是
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- workers文件
这些文件均可以在
/usr/hadoop-3.2.0/etc/hadoop下找到
workers文件
Slave00
Slave02
Slave03 # 主节点
旧版本以及网上的教程是修改etc/hadoop/slaves文件,但是新版已经移除了这一个文件,取而代之的是workers文件,上述设置代表我的集群有三个datanode结点
hadoop_env.sh 在hadoop根目录下执行
mkdir pids,用于存放pid文件
export JAVA_HOME=${JAVA_HOME} #设置JAVA_HOME的路径,需要再次指明
export HADOOP_HOME=${HADOOP_HOME}
export HADOOP_PID_DIR=/usr/hadoop-3.2.0/pids # pid文件根目录,不设置的默认值为/tmp,一段时间后/tmp下的文件会被清除,导致无法关闭hadoop集群
# 解决启动时警告 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
注意的是,如果之前没有设置JAVA_HOME的环境变量,此处直接这样引用会出现错误,改用绝对路径即可消除错误。
core-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 设置了主节点的ip -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Slave03:9000</value>
</property>
<!-- 设置了临时目录的地址 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/huangyc/hadoop_data/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave03:50090</value>
</property>
<property>
<!-- 配置网页端口访问 不配置的话 默认端口为9870-->
<name>dfs.namenode.http.address</name>
<value>Slave03:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
</configuration>
mapred-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Slave03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Slave03:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Slave03</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data/hadoop/yarn/nm</value>
</property>
</configuration>
1.4.4 从节点设置
将hadoop目录拷贝到从节点的对应目录 仿照主节点对应的数据目录设置,设置对应的数据目录(即/data一系列目录)
1.4.5 hadoop启动和测试
第一次开启时首先要初始化hdfs
cd /usr/hadoop-3.2.0
./bin/hdfs namenode -format
此处需要注意一个问题,第二次开启不需要再次初始化,遇到问题需要再次初始化,建议删除存放文件 上述配置文件中指明了存放数据的文件为dfs,到时候删除即可
主节点启动
cd /usr/hadoop-3.2.0/sbin
# 启动前
./start-all.sh
查看进程
# 主节点
[root@Slave03 sbin]# jps
28260 SecondaryNameNode
28810 ResourceManager
27706 DataNode
30236 Jps
29341 NodeManager
27326 NameNode
# 从节点
[root@Slave00 sbin]# jps
3570 DataNode
4115 NodeManager
22413 Worker
27503 Jps
查看对应的数据结点是否正确
[root@Slave03 sbin]# hdfs dfsadmin -report
Configured Capacity: 160982630400 (149.93 GB)
Present Capacity: 82032381952 (76.40 GB)
DFS Remaining: 82032345088 (76.40 GB)
DFS Used: 36864 (36 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
- hdfs主页
Slave03:50070,如果不行,试试默认端口9870 - hadoop主页
Slave03:8088
1.4.6 主要命令
- 启动集群:
./sbin/start-all.sh - 关闭集群:
./sbin/stop-all.sh
1.4.7 常见问题
stop-all.sh的时候hadoop的相关进程都无法停止
解决方案: 参考spark的常见问题,Hadoop的pid命名规则:
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pid
因此,这里的pid文件名为:
- hadoop-root-datanode.pid
- hadoop-root-namenode.pid
- hadoop-root-nodemanager.pid
- hadoop-root-resourcemanager.pid
- hadoop-root-secondarynamenode.pid
通过jps查看相关进程的pid,恢复这些pid文件即可使用stop-all.sh停止hadoop,根治方案参考spark常见问题部分
1.5 spark安装
1.5.1 安装配置
下载解压,复制到
/usr/spark-3.0配置环境变量
vi /etc/profile
# 配置spark环境
export SPARK_HOME=/usr/spark-3.0
export PATH=$PATH:$SPARK_HOME/bin
执行source /etc/profile令其生效
配置
spark-env.sh将conf文件夹下的spark-env.sh.template重命名为spark-env.sh,并添加以下内容: 在spark根目录下执行mkdir pids,用于存放pid文件
# 环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
export SCALA_HOME=/usr/share/scala
export HADOOP_HOME=/usr/hadoop-3.2.1
# 详细配置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=Slave03
export SPARK_LOCAL_DIRS=/usr/spark-3.0
export SPARK_DRIVER_MEMORY=16g # 内存
export SPARK_EXECUTOR_MEMORY=8g # 执行内存
export SPARK_WORKER_CORES=4 # cpu核心数
export SPARK_PID_DIR=/usr/spark-3.0/pids # pid文件根目录,不设置的默认值为/tmp,一段时间后/tmp下的文件会被清除,导致无法关闭spark集群
配置
slaves将conf文件夹下的slaves.template重命名为slaves,并添加以下内容:
Slave00
Slave02
Slave03 # 主节点
配置从节点(将spark目录复制到其他节点的同一个目录下)
scp -r root@192.168.123.24:/usr/spark-3.0 /usr/
在
sbin目录下使用start-all.sh启动集群
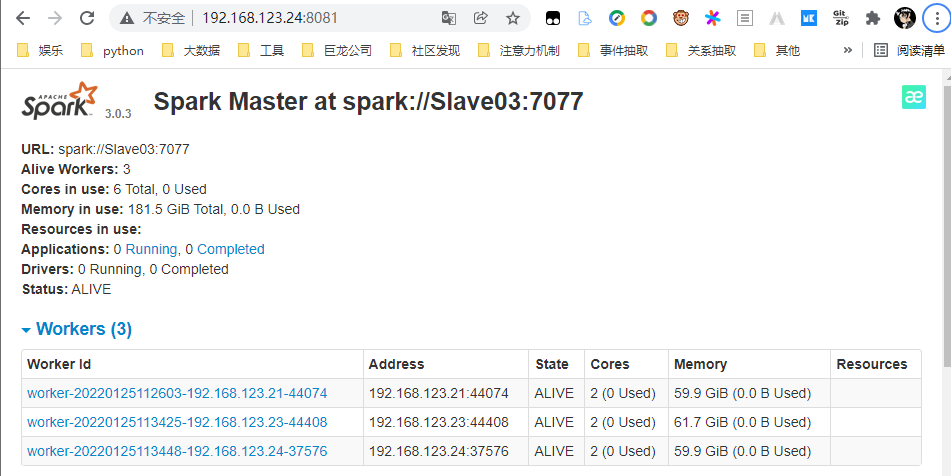
启动成功后,我们在浏览器输入Slave03:8080看到有三个结点,就代表我们安装成功了。
如果发现启动错误,请查看logs目录下的日志,自行检查配置文件!
1.5.2 日志配置
配置spark的执行日志等级,进入到spark根目录下的
conf目录cp log4j.properties.template log4j.properties,修改配置如下
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.sparkproject.jetty=WARN
log4j.logger.org.sparkproject.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
# 关闭警告
# WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
1.5.3 主要命令
- 启动集群:
./sbin/start-all.sh - 关闭集群:
./sbin/stop-all.sh
1.5.4 常见问题
stop-all.sh的时候spark的相关进程都无法停止
$SPARK_PID_DIR中存放的是pid文件,就是要停止进程的pid。其中$SPARK_PID_DIR默认是在系统的/tmp目录
系统每隔一段时间就会清除/tmp目录下的内容。到/tmp下查看一下,果然没有相关进程的pid文件了。
这才导致了stop-all.sh无法停止集群。
解决方案: $SPARK_PID_DIR下新建pid文件,pid文件命名规则如下
$SPARK_PID_DIR/spark-$SPARK_IDENT_STRING-$command-$instance.pid
$SPARK_PID_DIR默认是/tmp$SPARK_IDENT_STRING是登录用户$USER,我的集群中用户名是root$command是调用spark-daemon.sh时的参数,有两个:- org.apache.spark.deploy.master.Master
- org.apache.spark.deploy.worker.Worker
$instance也是调用spark-daemon.sh时的参数,我的集群中是1
因此pid文件名如下(名字不对的情况下,可以执行./start-all.sh,重新启动查看后,再执行./stop-all.sh进行本次集群的关闭,注意这里关闭的是本次打开的,之前无法关闭的进程仍然还在):
- spark-root-org.apache.spark.deploy.master.Master-1.pid
- spark-root-org.apache.spark.deploy.worker.Worker-1.pid
通过jps查看相关进程的pid,将pid保存到对应的pid文件即可,之后调用spark的stop-all.sh,即可正常停止spark集群
要根治这个问题,只需要在集群所有节点都设置$SPARK_PID_DIR,$HADOOP_PID_DIR和$YARN_PID_DIR即可
# 修改hadoop-env.sh,增加:
export HADOOP_PID_DIR=/home/ap/cdahdp/app/pids
# 修改yarn-env.sh,增加:
export YARN_PID_DIR=/home/ap/cdahdp/app/pids
# 修改spark-env.sh,增加:
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
2 pyspark
2.1 环境配置
2.1.1 基础环境
spark集群服务器配置环境变量,
vi /etc/profile
export PYSPARK_PYTHON=/root/anaconda3/envs/ray37/bin/python3.7
export PYSPARK_DRIVER_PYTHON=/root/anaconda3/envs/ray37/bin/python3.7
执行source /etc/profile使其生效
安装pyspark库
# 这里需要注意版本需要和spark的版本一致
pip install pyspark==3.0.3
# 在安装pyspark时默认会装上对应的py4j,如果没有的话,手动安装下
pip install py4j==0.10.9
对于spark服务器和work间环境不一致的情况
方式一: 重新安装python虚拟环境,使得路径完全一致
方式二: 配置软链接
ln -s 源文件 目标文件 # 需要事先建好路径 ln -s /opt/anaconda/install/envs/ray37/bin/python3.7 /root/anaconda3/envs/ray37/bin/python3.7
在服务器 liunx 环境上修改查看python的包路径site-package
from distutils.sysconfig import get_python_lib
print(get_python_lib())
2.1.2 graphx环境
安装graphframes
pip install graphframes==0.6
去graphframes官网下载对应jar包,这里spark集群是3.0.3,所以可以下载Version: 0.8.2-spark3.0-s_2.12这个版本的
复制到spark根目录下的jars目录中,集群中每个节点都需要
如果还会出错,可以把该jar包也复制一份到python环境下
/opt/anaconda/install/envs/ray37/lib/python3.7/site-packages/pyspark/jars
2.2 配置远程解释器
2.2.1 配置连接
配置连接的远程服务器
打开Pycharm -> Tools -> Deployment -> Configuration
点击加号,选择SFTP,给服务器取一个名字
点击SSH configuration后面的省略号 输入
服务器IP地址和账号密码,结束后测试一下连接情况Connection Parameters下的心跳可以设置10秒 确认后,保存退出当前窗口点击自动检测 ,选择远程服务器的工作路径 这里选的是,自己提前新建的空文件夹
/home/huangyc/hyc_test
Mappings下选择Local path,配置当前项目的路径 保存,退出
2.2.2 配置解释器
选择远程的解释器
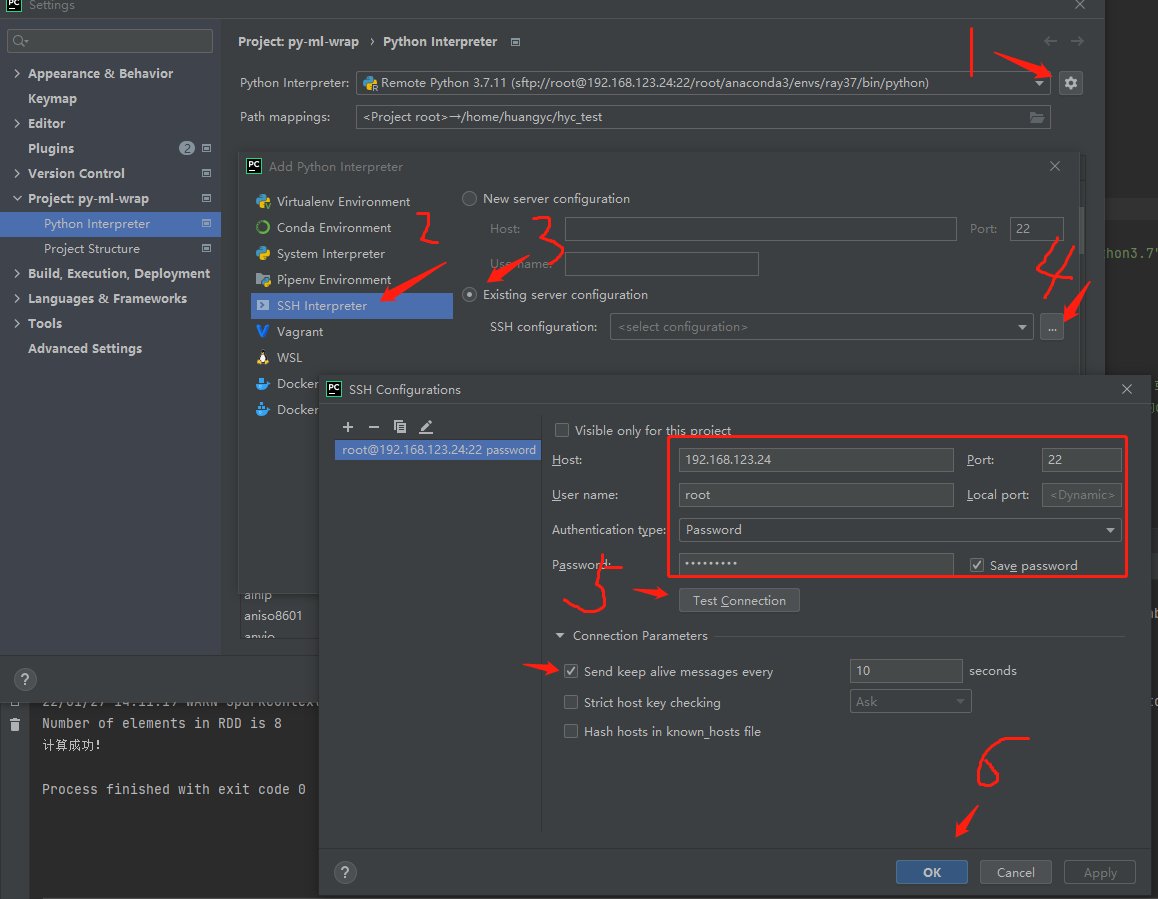
点击move即可next 配置路径,远程的选择自己之前新建的
/home/huangyc/hyc_testAutomatically upload ...表示会自动上传项目到服务器中
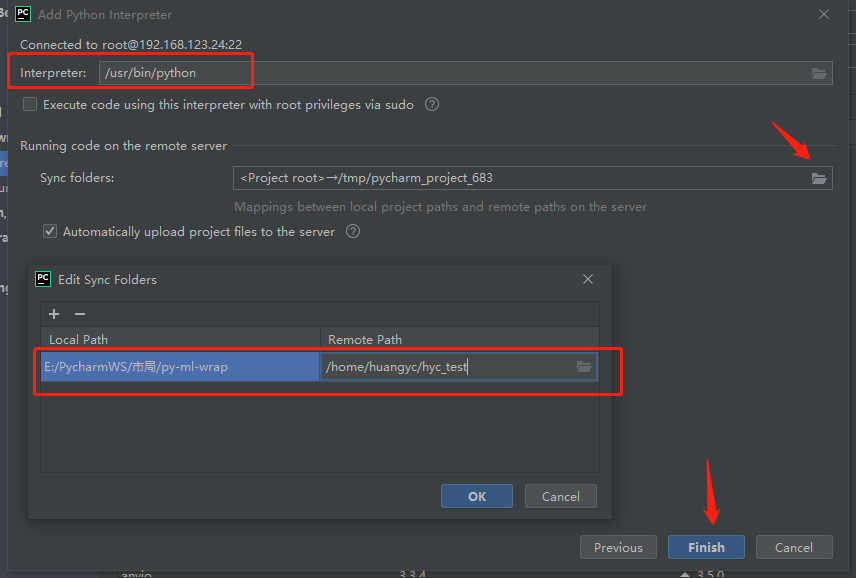
2.2.3 其它功能
- 在
Pycharm上显示远程代码:选择Tools -->Deployment-->Browse Remote Host - 更新代码:将本地代码上传到服务器上
Tools -->Deployment-->upload to - 服务器上代码下载到本地代码上
Tools -->Deployment-->Download from
2.3 测试例子
简单词统计 + pagerank例子
#!/usr/bin/env Python
# -- coding: utf-8 --
"""
@version: v1.0
@author: huangyc
@file: connenct_test.py
@Description:
@time: 2022/1/25 14:49
"""
import os
import platform
import traceback
from typing import List
from graphframes import *
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
py_root = "/root/anaconda3/envs/ray37/bin/python3.7"
os.environ["PYSPARK_PYTHON"] = py_root
os.environ["PYSPARK_DRIVER_PYTHON"] = py_root
is_local_py: bool = True
if is_local_py and platform.system().lower() == 'windows':
os.environ['JAVA_HOME'] = 'G:\Java\jdk1.8.0_201'
os.environ["SPARK_HOME"] = r"E:\PycharmWS\remote_spark\spark-3.0"
class PySparkClient:
def __init__(self, appname: str, master: str):
conf = SparkConf().setAppName(appname).setMaster(master) # spark资源配置
conf.set("spark.driver.maxResultSize", "4g")
conf.set("spark.executor.num", "4")
conf.set("spark.executor.memory", "2g")
conf.set("spark.executor.cores", "4")
conf.set("spark.cores.max", "16")
conf.set("spark.driver.memory", "2g")
try:
self.spark = SparkSession.builder.config(conf=conf).getOrCreate()
self.sc = self.spark.sparkContext
except:
traceback.print_exc() # 返回出错信息
def word_count(self, log_file: str):
if not self.sc:
return
log_data = self.sc.textFile(log_file).cache()
words_rdd = log_data.flatMap(lambda sentence: sentence.split(" "))
res = words_rdd.countByValue()
res_rdd = words_rdd.filter(lambda k: len(k) > 0).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 将rdd转为collection并打印
res_rdd_coll = res_rdd.takeOrdered(5, lambda x: -x[1])
for line in res_rdd_coll:
print(line)
def simple_test(self, words: List[str]):
if not self.sc:
return
counts = self.sc.parallelize(words).count()
print("Number of elements in RDD is %i" % counts)
test = self.spark.createDataFrame(
[('001', '1', 100, 87, 67, 83, 98), ('002', '2', 87, 81, 90, 83, 83), ('003', '3', 86, 91, 83, 89, 63),
('004', '2', 65, 87, 94, 73, 88), ('005', '1', 76, 62, 89, 81, 98), ('006', '3', 84, 82, 85, 73, 99),
('007', '3', 56, 76, 63, 72, 87), ('008', '1', 55, 62, 46, 78, 71), ('009', '2', 63, 72, 87, 98, 64)],
['number', 'class', 'language', 'math', 'english', 'physic', 'chemical'])
test.show()
test.printSchema()
test.select('number', 'class', 'language', 'math', 'english').describe().show()
print("============ simple_test over ============")
def simple_graph(self):
# Create a Vertex DataFrame with unique ID column "id"
spk = self.spark
v = spk.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
], ["id", "name", "age"])
# Create an Edge DataFrame with "src" and "dst" columns
e = spk.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
], ["src", "dst", "relationship"])
# Create a GraphFrame
g = GraphFrame(v, e)
# Query: Get in-degree of each vertex.
g.inDegrees.show()
# Query: Count the number of "follow" connections in the graph.
print(g.edges.filter("relationship = 'follow'").count())
# Run PageRank algorithm, and show results.
results = g.pageRank(resetProbability=0.1, maxIter=1)
res = results.vertices.select("id", F.bround("pagerank", scale=4).alias('pagerank'))
res.orderBy(res.pagerank.desc()).show(5)
def stop(self):
try:
self.sc.stop()
except:
pass
if __name__ == '__main__':
appname = "test_hyc00" # 任务名称
master = "spark://192.168.xx.xx:7077" # 单机模式设置
# master = "local"
py_spark_client = PySparkClient(appname=appname, master=master)
# 简单功能测试
all_words = ["scala", "java", "hadoop", "spark", "akka", "spark vs hadoop",
"akka", "spark vs hadoop", "pyspark", "pyspark and spark"]
py_spark_client.simple_test(words=all_words)
# 文档词频统计
logFile = r"hdfs://192.168.xx.xx:9000/test_data/README.md"
py_spark_client.word_count(log_file=logFile)
py_spark_client.simple_graph()
# 关闭客户端连接
py_spark_client.stop()
执行方法
可以直接在pycharm中执行,这里pycharm使用的是远程的python环境,这里执行时的内存是默认值 1024.0 MiB
在pycharm中执行可能需要加上变量设置,但使用
spark-submit则可以不需要os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/envs/ray37/bin/python3.7" os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/envs/ray37/bin/python3.7"或者执行以下命令执行,这里执行时的内存是spark中配置的 8.0 GiB
./bin/spark-submit --master spark://192.168.xx.xx:7077 /home/huangyc/hyc_test/tests/pyspark_test/connenct_test.py
2.4 本地连接
除了配置远程服务器的py解释器,还可以配置本地的模式
需要在spark集群中配置host映射,通过
vi /etc/hosts命令打开hosts文件,添加本地的主机名映射
# hyc
10.10.0.xx DSE-20191111ZOU
最后执行/etc/init.d/network restart刷新DNS
如果没有的话,可能会报错误
Caused by: java.io.IOException: Failed to connect to DSE-20191111ZOU:65320
Caused by: java.net.UnknownHostException: DSE-20191111ZOU
py代码中需要添加以下的环境参数才能连接上spark集群
import os
# 配置集群的python环境路径
py_root = "/root/anaconda3/envs/ray37/bin/python3.7"
os.environ["PYSPARK_PYTHON"] = py_root
os.environ["PYSPARK_DRIVER_PYTHON"] = py_root
# 配置本地Jdk路径,版本尽量和spark集群的一致
os.environ['JAVA_HOME'] = 'G:\Java\jdk1.8.0_201'
# 配置本地的spark路径,这里直接从spark集群copy一份下载即可
os.environ["SPARK_HOME"] = r"E:\PycharmWS\remote_spark\spark-3.0"
class PySparkClient:
def __init__(self, appname: str, master: str):
conf = SparkConf().setAppName(appname).setMaster(master) # spark资源配置
# 以下的参数不用全部配置,看自己的需求
conf.set("spark.driver.maxResultSize", "4g")
conf.set("spark.executor.num", "4")
conf.set("spark.executor.memory", "2g")
conf.set("spark.executor.cores", "4")
conf.set("spark.cores.max", "16")
conf.set("spark.driver.memory", "2g")
try:
self.spark = SparkSession.builder.config(conf=conf).getOrCreate()
self.sc = self.spark.sparkContext
except:
traceback.print_exc() # 返回出错信息
⚡: 本地的python版本尽量和spark集群上的一致,避免不必要的错误